Ángel Alex ander Cabrera
Regularizing Black-box Models for Improved Interpretability
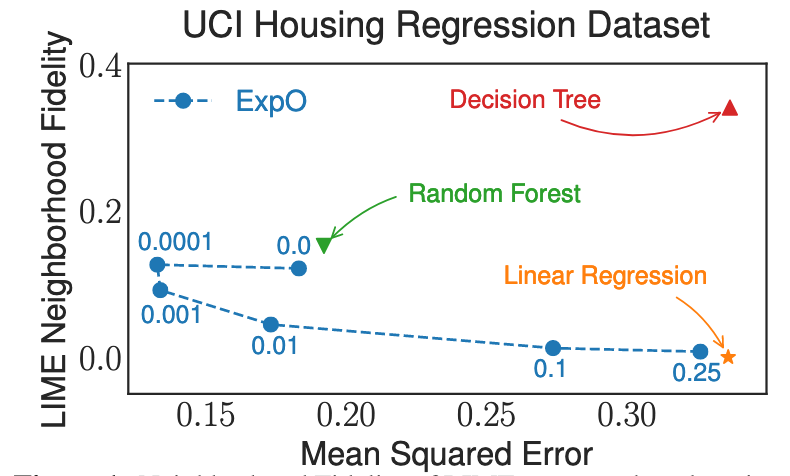
Most of the work on interpretable machine learning has focused on designing either inherently interpretable models, which typically trade-off accuracy for interpretability, or post-hoc explanation systems, which tend to lack guarantees about the quality of their explanations. We explore a hybridization of these approaches by directly regularizing a black-box model for interpretability at training time - a method we call ExpO. We find that post-hoc explanations of an ExpO-regularized model are consistently more stable and of higher fidelity, which we show theoretically and support empirically. Critically, we also find ExpO leads to explanations that are more actionable, significantly more useful, and more intuitive as supported by a user study.
Citation
Regularizing Black-box Models for Improved InterpretabilityGregory Plumb, Maruan Al-Shedivat, Ángel Alexander Cabrera, Adam Perer, Eric Xing, Ameet Talwalkar
Conference on Neural Information Processing Systems (NeurIPS). Vancouver, 2020.
BibTex
@inproceedings{plumb2020expo, author = {Plumb, Gregory and Al-Shedivat, Maruan and Cabrera, \'{A}ngel Alexander and Perer, Adam and Xing, Eric and Talwalkar, Ameet}, title = {Regularizing Black-Box Models for Improved Interpretability}, year = {2020}, isbn = {9781713829546}, publisher = {Curran Associates Inc.}, address = {Red Hook, NY, USA}, booktitle = {Proceedings of the 34th International Conference on Neural Information Processing Systems}, articleno = {883}, numpages = {11}, location = {Vancouver, BC, Canada}, series = {NIPS'20} }